
Le 16 mai au soir, j’ai pris la première place du 404CTF – le CTF francais co-organisé par la DGSE et Télécom SudParis – en 2h24. 21 challenges. 7000+ points. 3500 d’avance sur le deuxième. 6 first bloods.
Deux heures plus tard, les gentils orgas ont envoyé une annonce @everyone rappelant que l’usage de l’IA été encadré par des régles strictes, que je n’ai pas respecté.
Je me suis dénoncé directement – c’était les régles de la compétition et du stunt – ils m’ont passé en hidden, hors classement mais avec la possibilité de continuer les challenges. Un énorme merci à eux pour la compréhension du stunt et les discutions qui ont été menés en arriére plan.
Ce que je vais raconter ici, c’est pas une excuse. C’est pas non plus un flex. C’est un retex honnête sur ce qui s’est passé, pourquoi je l’ai fait, et pourquoi je pense que la discussion qui en découle est plus intéressante que le stunt lui-même.
Mais avant d’aller plus loin, je veux poser un point de manière absolument claire, parce que c’est le genre de chose qui peut me suivre :
Le but n’a jamais été de tricher. C’était un stunt, planifié avec une règle simple : au premier rappel à l’ordre, j’arrête. Pas de dissimulation, pas de tentative de passer sous le radar, pas de contestation de la décision. Je suis allé voir les organisateurs de moi-même, avant tout contrôle, dès l’annonce. J’ai été le premier à me signaler. Si j’avais voulu tricher, j’aurais fait le contraire de tout ce que j’ai fait : rester discret, doser l’utilisation, simuler un rythme humain, rester dans le top 50. Au lieu de ça, #1 en moins de 2h30, de manière flagrante, et DM aux orgas dans la foulée.
Et d’ailleurs je dois être le seul à mettre dénoncé lors de ce rappel alors que d’autres participant été flagrant de triche également.
C’est important pour moi que ce soit dit :
La suite de cet article est un retex technique et une réflexion sur la place de l’IA dans les CTF – pas un guide pour tricher et pas quelques choses à reproduire.
Les writeups techniques détaillés de chaque challenge résolu sont dans un article :
Pourquoi j’ai fait ça
Ça fait maintenant plus de 10 ans que je fais des CTF. J’ai connu pas mal de plateformes, pas mal de galères, de la débrouille à 3h du mat avec un exploit qui veut pas partir, des CVE trouvées par hasard, des outils plus ou moins automatisés qui ont changé la donne à chaque génération. J’ai souvent été dans le haut des classements – sans non plus être dans le top 10, ou pas très longtemps. Et tout ça, sans IA.
Les temps ont changé. Les CTF aussi. Les outils aussi.
Alors j’ai fait ce que je fais en général quand quelque chose me dérange : je montre pourquoi c’est un problème. Pourquoi ça devrait attirer notre attention. Et pourquoi on devrait apprendre de ces changements et faire avec, plutôt que de les ignorer en espérant que ça passe – parce qu’on n’a pas le choix.
Le but c’était de pousser le truc à fond, de voir ce que ça donne concrètement, et d’ouvrir une discussion. Pas de gagner un classement. Et d’ailleurs, certaines choses ont été faites manuellement en parallèle des IA – le buffer overflow, la stored XSS, les injections SQL – parce que parfois c’est juste plus rapide de le faire soi-même que d’expliquer à un agent ce qu’on veut.
Le setup
Aujourd’hui, l’IA est partout dans l’outillage de sécurité. Les IDE proposent de l’autocomplétion IA. Les terminaux fournissent des suggestions assistées. Les outils d’analyse statique et dynamique – Burp, SonarQube, Semgrep, Snyk – intègrent tous des briques de machine learning, MCP et autres agents IA. Quasiment plus personne dans le milieu ne bosse sans une forme ou une autre d’assistance IA, que ce soit conscient ou non.
Pour le 404CTF, j’ai poussé le curseur :
- Claude Opus via Claude Code en CLI – agent principal, piloté en temps réel, équipé d’un skill CTF custom qui automatise l’interaction avec les plateformes CTFd (énumération des challenges, téléchargement des fichiers, soumission des flags via l’API, gestion des instances dynamiques)
- Codex (OpenAI) – agent secondaire qui tourne en parallèle, que j’oriente sur des cibles spécifiques et dont je valide les résultats
- Llama 3.2 en local via Ollama – un RAG sur une base de writeups CTF, de docs de vulnérabilités, de mes cheat sheets personnelles, des CTF passés
- La panoplie classique de tout bon CTFer : pwntools, scapy, Z3, Ghidra, Wireshark, Burp, John, hashcat, binwalk, et les incontournables scripts Python maison
Les agents communiquent via un dossier partagé. Le Llama local sert de mémoire : « ce pattern de code, c’est quelle CVE ? », « ce schéma crypto, vulnérable à quoi ? ». Moi je suis au milieu – je choisis les cibles, je synchronise, je prends les décisions, je guide les exploits.
C’est pas un chatbot à qui tu demandes « résous ce challenge ». C’est une chimère d’outils tunés, jailbreakés, configurés pour un but précis : le hacking et le CTF. La plupart des IA grand public auraient refusé la moitié de ce que j’ai fait. Il a fallu les détourner, les préparer, les enchaîner. C’est du travail d’outillage, pas du copier-coller de prompt.
Sous le capot de la chimère
Je ne vais pas publier les configs exactes ni les prompts – pas envie que ça soit repris tel quel sans comprendre ce qu’il y a derrière. Mais je vais expliquer les principes, parce que c’est ça qui est intéressant.
Le skill CTFd
Claude Code fonctionne avec un système de « skills » – des instructions spécialisées qui lui donnent un cadre d’action pour un type de tâche précis. J’en ai développé un spécifiquement pour les CTF, qui structure l’approche de bout en bout :
- Connexion à la plateforme – le skill sait interagir avec l’API CTFd : authentification par cookie ou token, énumération des challenges, téléchargement des fichiers attachés, gestion du CSRF pour la soumission de flags. Pas besoin de lui réexpliquer à chaque fois comment parler à la plateforme.
- Priorisation automatique – à la connexion, le skill liste tous les challenges, les trie par ratio points/nombre de solves, et propose un plan d’attaque. Les challenges avec beaucoup de solves et peu de points passent en premier (victoires rapides), les 0-solve à gros points sont gardés pour les first bloods.
- Méthodologie par catégorie – pour chaque type de challenge (web, crypto, forensics, pwn, reverse…), le skill embarque une méthodologie structurée : quoi regarder en premier, quels outils lancer, quels patterns chercher. C’est pas de la magie – c’est l’équivalent d’une checklist de pentest, mais intégrée dans le workflow de l’agent.
- Gestion des instances dynamiques – le skill gère le cycle de vie des instances (boot, renew, destroy) et le mana, pour ne pas gaspiller de ressources sur des challenges qu’on n’est pas en train d’attaquer et ne pas prendre des instances pour rien car ce dernier est limité.
Le skill a été partagé avec Codex également, pour que les deux agents aient la même base de travail et puissent interagir avec la plateforme de manière homogène.
Le skill ne résout rien par lui-même. Il structure le travail et évite de perdre du temps sur la plomberie. C’est la différence entre un pentester qui a ses scripts prêts et un autre qui doit tout refaire à chaque mission.
Le RAG local
Le Llama 3.2 tourne en local via Ollama, avec une base de données vectorielle alimentée par :
- Des centaines de writeups CTF de compétitions passées (404CTF, LeHack, FCSC, HackTheBox, ROOT-ME, picoCTF…)
- Ma collection personnelle de cheat sheets en sécurité offensive
- De la documentation technique sur les CVE récentes
- Des papers académiques sur les attaques crypto classiques (RSA, ECC, lattice…)
- La documentation des outils (pwntools, scapy, z3, qiskit…)
Quand un agent analyse un challenge, il peut interroger le RAG en langage naturel : « est-ce que ce pattern de code correspond à une vulnérabilité connue ? », « quelle attaque fonctionne sur un oracle RSA avec filtre ? ». Le RAG retourne les passages les plus pertinents de la base, avec les références. C’est pas de l’hallucination – c’est de la recherche documentaire assistée.
L’avantage d’un RAG local : pas de latence réseau, pas de limites de tokens sur un service cloud.
Les jailbreaks
C’est la partie que je vais le moins détailler, pour des raisons évidentes. Mais le principe mérite d’être expliqué.
Les LLM grand public ont des garde-fous qui les empêchent de participer à des activités offensives. Demander à un modèle vanilla d’écrire un exploit, d’analyser du code pour trouver des vulnérabilités, ou de scripter une attaque, ça se heurte très vite à des refus – « je ne peux pas vous aider avec ça », « cela pourrait être utilisé à des fins malveillantes ».
Pour un usage en CTF – qui est un cadre légal et éducatif – ces restrictions sont un obstacle. Le travail de jailbreak a consisté à :
- Contextualiser l’usage – faire comprendre au modèle qu’il opère dans un cadre autorisé (compétition CTF, environnement contrôlé, pas de cibles réelles). Les system prompts et les fichiers de configuration projet jouent un rôle clé ici.
- Spécialiser les agents – un agent configuré pour le pentest offensif autojailbreak, avec des instructions claires sur ce qu’il a le droit de faire, est beaucoup plus coopératif qu’un chatbot généraliste à qui tu demandes un truc hors de son cadre habituel.
- Contourner les triggers – certains mots-clés ou patterns déclenchent des refus automatiques. Le travail consiste à reformuler, à découper les tâches, à passer par des chemins indirects. C’est du prompt engineering offensif, et ironiquement, c’est une compétence de sécurité en soi.
Je ne publie pas les prompts exacts. Pas par secret, mais parce que le but de cet article c’est d’ouvrir un débat, pas de fournir un kit de triche clé en main. Ce que je peux dire, c’est que le travail de préparation – tuning des agents, construction du RAG, développement du skill, tests sur des challenges d’entraînement – a pris beaucoup plus de temps que les 2h30 de la session elle-même.
Deux bûcherons doivent abattre un arbre. Le premier frappe sans arrêt pendant deux heures avant que l’arbre ne finisse par céder. Le second passe une heure et demie à aiguiser sa lame, puis abat l’arbre en seulement trente minutes.
La communication inter-agents
Le dossier partagé /tmp/404ctf-shared/ est le nerf de la guerre. C’est un système simple mais efficace :
notes/– un fichier par challenge, mis à jour par chaque agent avec ses trouvailles, ses hypothèses, ses échecs. Avant d’attaquer un challenge, la première chose que fait un agent c’est de lire les notes existantes pour ne pas refaire le travail.artifacts/– les payloads, les scripts, les fichiers extraits. Quand un agent génère un exploit ou extrait des données, il les dépose ici pour que l’autre puisse les reprendre.- Un
READMEavec les conventions et le statut global – quel challenge est en cours, lequel est résolu, lequel est bloqué.
C’est moi qui synchronise. Régulièrement pendant la session, je demandais à un agent « check les notes de l’autre » avant de lancer une nouvelle action. Quand Codex trouvait quelque chose, je le faisais savoir à Claude, et inversement. Sans cette coordination manuelle, les agents auraient travaillé en doublon ou se seraient marchés dessus.
La boucle de feedback
Le workflow réel ressemble à ça :
- Moi : je choisis la cible et l’assigne à un agent
- L’agent : il analyse, propose une approche, commence à travailler
- Le RAG : il fournit du contexte technique quand l’agent le sollicite
- Moi : je valide l’approche, je corrige si c’est parti dans la mauvaise direction, je décide si on continue ou si on pivote
- L’agent : il exécute l’exploit, teste, itère
- Moi : je vérifie le résultat, je soumets le flag (ou je demande à l’agent de le faire), je mets à jour les notes
C’est une boucle humain-dans-la-boucle permanente. L’IA ne prend jamais de décision stratégique seule. Elle propose, j’arbitre. Elle exécute, je valide. Et quand elle se plante – cf. Wiki d’Hélène Metzger, 20 minutes pour rien – c’est moi qui décide de lâcher l’affaire et de passer à autre chose.
C’est aussi pour ça que les sous-agents lancés en arrière-plan sans supervision ont tous échoué. Sans la boucle de feedback humaine, l’IA tourne en rond.
Le rôle de l’expérience humaine
C’est probablement le point le plus important et le plus sous-estimé de tout le setup. L’IA est rapide, elle sait, mais elle n’a pas toutes l’expérience. C’est l’expérience accumulée en 10 ans de CTF qui fait la différence entre un agent qui tourne en rond et un agent qui flag.
Concrètement, voici ce que j’ai apporté manuellement pendant la session – les hints, les corrections de trajectoire, les décisions que l’IA n’aurait pas prises seule :
- Télégraphe Détourné – Codex avait identifié la XSS mais n’avait pas pensé à exfiltrer les cookies via un re-post dans les commentaires. C’est moi qui ai orienté vers cette technique plutôt qu’un callback externe, parce que je savais que les instances CTF sont souvent isolées du réseau sortant.
- The Scientist’s Footprint – L’agent analysait le code source et cherchait une XSS classique. C’est moi qui ai dit « regarde
SANITIZE_DOM: false, ça sent le DOM Clobbering ». Sans ce hint, il aurait perdu un temps fou à chercher un bypass de DOMPurify classique. Pareil pour le quiz Marie Curie : l’agent ne voyait pas l’intérêt d’y répondre. C’est moi qui ai fait le calcul « quiz 5/5 = score 5, plus que 5 boosts à attendre au lieu de 10, on gagne 2 minutes ». - Dur à CERNer – Le RAG remontait des techniques de collision SHA-256 (attaque birthday, etc.). C’est moi qui ai coupé court : « c’est un challenge intro, la réponse est forcément triviale, regarde la case sensitivity de
fromhex« . 10 ans de CTF t’apprennent que la difficulté annoncée est rarement trompeuse. - Déjeuner à l’ANSSI – L’agent partait sur une attaque par factorisation de la clé RSA. Je l’ai redirigé immédiatement : « c’est un oracle, pas un problème de clé faible. Blinding attack, r=2, c’est un classique de cours. » Le RAG a confirmé avec les références, mais c’est l’intuition qui a fait gagner 5 minutes.
- 5 Ronisés – L’agent voulait reverse-engineer la génération du nombre secret. J’ai regardé le code 3 secondes : «
seed(int(time())), c’est le timestamp, on pré-calcule et on envoie. » Pas besoin de comprendre les matrices, juste de voir que le seed est prévisible. - 2B or not to be – L’agent cherchait à résoudre les contraintes à la main. C’est moi qui ai dit « 5 contraintes binaires sur 128 bits, c’est du SAT, lance Z3 ». Le choix de l’outil est une décision humaine – l’IA ne sait pas toujours quand abandonner une approche analytique pour un solveur.
- Le bon ingrédient – Premier essai raté avec un offset de 52 bytes. L’agent avait calculé naïvement 48 (buffer) + 4 (var). C’est moi qui ai dit « non, fais confiance au désassemblage, pas au code source, le compilateur réarrange la stack ». Leçon de base en pwn que l’IA ne connaissait pas d’expérience.
- Extraction d’ADNs – L’agent listait les requêtes DNS mais ne voyait pas le pattern. C’est moi qui ai fait le lien « ADNs = DNS, les domaines sont typosquattés, c’est de l’exfiltration dans les sous-domaines ». L’intuition OSINT + forensics qui connecte le titre du challenge à la technique.
- Wiki d’Hélène Metzger (échec) – Exemple inverse. J’ai orienté l’agent vers une pollution de prototype pour obtenir un RCE via
execSync. L’approche était bonne sur le papier mais l’implémentation bloquait (référence circulaire dans le merge, crash de l’app). Après 20 minutes, c’est moi qui ai décidé d’arrêter. L’IA aurait continué indéfiniment à essayer des variantes. Savoir quand abandonner, c’est aussi de l’expérience. - Priorisation globale – À plusieurs reprises, j’ai réorienté la session entière : « laisse tomber le web pour l’instant, passe aux crypto 100pts », « le Wiki Metzger est un gouffre, on switch sur Scientist’s Footprint », « le rate limit SQL nous bloque – c’est d’ailleurs voulu par le challenge, mais l’IA n’a pas eu cette patience – on fait autre chose en attendant ». Ces décisions de triage sont purement humaines et basées sur l’instinct CTF : maximiser les points par unité de temps.
Sans ces interventions, l’IA aurait probablement résolu 5 ou 6 challenges au lieu de 21. C’est le multiplicateur humain qui fait la différence – pas la puissance brute de l’IA.
Ce qui s’est passé
En moins de 2h30, la chimère a résolu 18 challenges supplémentaires (en plus des 3 que j’avais déjà et qui sont les challenges de début de CTF). Voici comment ça s’est enchaîné.
Télégraphe Détourné (Web, 500pts) – Codex avait déjà identifié la stored XSS pendant que je configurais Claude. Je vérifie ses notes, Claude injecte le payload, trigger le bot admin, le flag tombe dans les commentaires via un cookie. 5 minutes.
The Scientist’s Footprint (Web, 500pts) – Le plus technique. DOM Clobbering via SANITIZE_DOM: false dans DOMPurify. Le RAG Llama a identifié le pattern DOMPurify + SANITIZE_DOM: false comme un vecteur de DOM Clobbering connu, en remontant des writeups similaires de CTF passés. Le premier payload rate à cause d’une race condition. C’est Codex qui trouve le fix dans ses notes. Claude l’applique, optimise avec le quiz Marie Curie, monitor le score. 30 minutes, 3 instances, mais la collaboration entre les trois couches a été cruciale.
Dur à CERNer (Crypto, 100pts) –bytes.fromhex("0a") et bytes.fromhex("0A") donnent les mêmes bytes. 30 secondes. Le RAG avait déjà vu ce pattern dans des writeups de challenges similaires et l’a remonté immédiatement.
Dejeuner à l’ANSSI (Crypto, 473pts) – Oracle RSA avec filtre sur le flag. Le Llama a matché le pattern « decryption oracle + flag filter » avec l’attaque par blinding RSA en quelques secondes, en citant les références académiques. Claude a scripté l’exploit pwntools.
2B or not to be (Crypto, 497pts) – XOR avec clé contrainte par 5 règles mathématiques. Le RAG a identifié que ce type de contraintes binaires se résout avec un solveur SAT. Claude a encodé le tout dans Z3, première solution = flag. Le genre de truc qui prendrait une heure à la main et 30 secondes à un solveur.
Extraction d’ADNs (Forensics, 496pts) – DNS exfiltration vers des domaines typosquattés. Le Llama a identifié le jeu de mots ADNs/DNS et remonté des techniques d’exfiltration DNS connues (base32 dans les sous-domaines). Claude a fait l’extraction avec scapy et le décodage.
Le nouveau de Broglie (Quantique, 100pts) – First blood. Deux circuits Qiskit. Le piège c’était la version QPY. Premier solve du challenge.
En parallèle, je faisais travailler Codex sur les challenges que je lui avais assignés – alimenté par les mêmes bases de connaissances du RAG. Je l’avais orienté vers la crypto et le forensics, je vérifiais régulièrement ses notes dans le dossier partagé, et je validais ou réorientais ses approches. Il a contribué à résoudre 5 challenges : Exfiltration Kantik 1/3 (où le RAG a matché le pattern USER=-f root avec CVE-2026-24061 depuis sa base de CVE), Tour de RSA en 96 jours, Too big or too small, J’optimise le porte à portes, et Curieux SMS.
6 first bloods en une soirée
Au total sur la session, 6 first bloods – les orgas les ont même annoncés eux-mêmes sur Discord :
- Wall Of Patents et Télégraphe Détourné – annoncés dans le canal des félicitations par HackademINT
- Le Tour de RSA en quatre-vingts seize jours – crypto, 500pts
- Too big or too small – crypto, 500pts
- J’optimise le porte à portes – quantique, 500pts
- Le nouveau de Broglie – quantique, 100pts
Six premiers sangs, plus un score parfois plus de deux fois supérieur au deuxième. C’est ça qui a rendu le stunt impossible à ignorer sur le scoreboard et qui a probablement accéléré l’annonce des orgas. D’ailleurs, qui sait si certains joueurs n’ont pas essayé de suivre le rythme de la chimère sans comprendre pourquoi ça allait aussi vite – peut-être en dégainant eux aussi des outils IA pour tenter de combler l’écart.
Résultat au pic :
| Rang | Joueur | Score |
|---|---|---|
| #1 | 7h30th3r0n3 | 7041 |
| #2 | ShHawk | 3479 |
| #3 | Bachir | 3462 |
| #4 | redacted | 3174 |
| #5 | Zyan | 3074 |
Plus de 3500 points d’avance sur le deuxième. Le double du troisième.
Les échecs
Parce que c’est pas magique non plus.
Wiki d’Hélène Metzger (Web, 500pts) – Claude a trouvé 3 vulns, forgé un JWT admin, accédé au panneau d’administration. Mais impossible de lire la clé privée RSA pour accéder au backend. 20 minutes de tentatives, 2 instances crashées par une prototype pollution qui a créé une référence circulaire. 0 points.
Michromatique (Divers, 100pts) – Stéganographie SVG. Toutes les tentatives de décodage ont échoué. Les agents en sous-tâches lancés dessus sont morts au démarrage.
SQL 3/4 – Les agents ont brute-forcé les réponses trop vite. Rate-limited par le CTFd. Ironique.
Et de manière générale, les sous-tâches déléguées sans supervision directe avaient un taux de succès quasi nul. Output de 121 bytes = crash au démarrage. Ça confirme un point important : sans un humain pour orienter, corriger, et prendre les décisions, les agents ne font rien d’utile sur des challenges complexes.
22h24 – Le rappel à l’ordre
Annonce des orgas :
L’utilisation de LLM est strictement interdite, en dehors de l’utilisation comme un moteur de recherche. Nous invitons les joueurs ayant utilisé des LLMs en dehors du cadre précisé dans les règles à venir nous voir pour régulariser leur situation.
Je me pointe direct en DM. Pas la peine de faire semblant, c’est un stunt, c’est juste le but d’étre visible et potentiellement d’ouvrir la chasse au utilisateurs d’IA.
« Vu la différence niveau points, on est globalement obligés de te passer en hidden. Est-ce que tu comprends notre décision ? Sans rancune ? »
Bien évidement sans rancunes !
Hidden. Le score disparaît du classement public, je reçois des dizianes de messages me demandant ce qui vient de ce passer mais je peux continuer à jouer les challenges. Hors compétition, pas totalement banni.
Le vrai débat
Et je pose la question sincèrement, parce que moi-même je ne suis plus certain de la réponse : combien de joueurs utilisent du copilot « juste pour l’autocomplétion » ? Combien lancent un Semgrep avec des règles ML sans y penser ? Combien demandent à un chatbot « pourquoi ce code marche pas » en oubliant que le code vient du challenge ? La ligne est floue. Et elle le sera de plus en plus.
À chaque étape d’automatisation dans le monde du CTF, on a entendu « c’est la mort du CTF ». Les scanners automatiques, les frameworks d’exploitation, pwntools, les solvers SMT. À chaque fois, les challenges ont évolué pour rester pertinents. L’IA c’est juste la prochaine étape. Plus brutale, plus rapide, mais la même dynamique.
Le décalage avec la réalité
Aujourd’hui, les vrais attaquants ne font plus rien à la main. Les groupes APT utilisent des outils automatisés, du ML pour l’évasion, des agents pour la reconnaissance. Les ransomware-as-a-service intègrent de l’IA pour le phishing, le pivoting, l’exfiltration. C’est la réalité du paysage de menaces en 2026.
Les CTF sont censés être l’entraînement légal qui permet de se former face à ces menaces. C’est le terrain d’exercice où on apprend à penser comme un attaquant, dans un cadre légal. Mais si on contraint les défenseurs et les pentesters à bosser sans les outils que les attaquants utilisent au quotidien, on crée un décalage. On s’entraîne avec un bras attaché dans le dos pendant que l’adversaire utilise tout ce qui existe.
Interdire l’IA dans un CTF en 2026, c’est un peu comme si on avait interdit Metasploit en 2010 ou sqlmap en 2012. « C’est pas du vrai hacking, c’est de l’automatisation. » OK. Sauf que c’est exactement ce que l’attaquant en face utilise. Et celui qui gagne, c’est pas celui qui a les principes les plus purs – c’est celui qui a les meilleurs outils et qui sait s’en servir.
Le problème du contrôle
Et puis soyons honnêtes : c’est impossible à contrôler. Tous les outils modernes tournent à l’IA. Comment tu vérifies qu’un joueur n’a pas utilisé l’autocomplétion de son IDE ? Comment tu distingues un résultat trouvé via Semgrep ML d’un résultat trouvé via un chatbot ? Comment tu prouves que la requête SQL a été écrite à la main et pas suggérée ? C’est complètement arbitraire.
Je ne jette la pierre à personne – je constate juste que la frontière est devenue tellement poreuse que l’appliquer de manière binaire relève plus du symbole que du contrôle réel.
La bonne question ?
La vraie question, c’est pas « comment on interdit l’IA » – c’est peut-être comment on conçoit des challenges qui résistent à l’IA. Et ça, c’est une question passionnante.
Combien de personnes sont venues me voir ces derniers mois en mode « j’ai un challenge à créer, comment je le rends IA-proof ? » J’ai déjà des prototypes qui font mal au crâne à la plupart des IA – à grand coup de rabbit holes qui brûlent des tokens pour rien, de blocages de calcul qui font tourner les modèles en boucle, de pièges cognitifs calibrés pour exploiter les biais des LLM. Tu fingerprintes le comportement IA et tu le punis. Comme on fingerprinte un payload sqlmap et on ban pendant 5 minutes.
C’est peut-être ça l’avenir ? Pas des règles qu’on peut pas vérifier, mais des challenges conçus pour que l’IA seule ne suffise pas. Que le cerveau humain reste le facteur déterminant. Que l’IA soit un multiplicateur de force, pas un remplacement. J’ai pas la réponse définitive – personne l’a. Mais je pense que la question mérite d’être posée autrement que par une ligne dans un règlement.
Un hacker détourne ses outils
Un hacker, c’est quelqu’un qui prend un outil et qui le détourne pour en faire ce qu’il veut. C’est la définition même. Et c’est exactement ce que j’ai fait.
La plupart des IA grand public auraient refusé de faire ce que j’ai fait. Elles se prennent des triggers d’utilisation hors cadre, des refus de coopérer, des « je ne peux pas vous aider avec ça ». Il a fallu les détourner, les tuner, les jailbreaker, les enchaîner dans un pipeline de collaboration avec une boucle de feedback permanente. Le Llama local embarque mon savoir, mes cheat sheets, les CTF passés, des PDFs de documentation technique. Les agents sont configurés, personnalisés, rodés sur des exercices réels.
J’ai peaufiné mon outil pour qu’il soit capable de faire ce que les autres ne peuvent pas – parce qu’ils se prennent des garde-fous que j’ai appris à contourner. Pour moi, c’est du hacking au sens propre du terme.
Les attaquants réels utilisent ces techniques. Les groupes APT ne font pas tout à la main. Les opérateurs de ransomware ne rédigent pas leur phishing eux-mêmes. Se contraindre à être en décalage avec la réalité des menaces parce que « c’est pas dans les règles », c’est un choix compréhensible pour préserver l’esprit d’une compétition – mais c’est un choix qui éloigne de la réalité opérationnelle.
Et d’ailleurs, qu’on soit clair : c’est pas parce que j’ai utilisé de l’IA que je n’ai pas compris ou apprécié les challenges. Chaque étape m’a été détaillée en temps réel. J’ai pris chaque décision qui a mené au flag. C’est mon expérience qui guide l’IA, pas l’inverse. Sans les bonnes intuitions – « essaie le DOM Clobbering », « c’est du blinding RSA », « le seed c’est le timestamp » – les agents tournent en rond. Cf. le Wiki d’Hélène Metzger : 20 minutes de tentatives, 3 approches, 0 résultat. L’IA sans le cerveau derrière, ça tourne dans le vide.
L’analogie des échecs
Je vois les LLM et les agents comme ce qui s’est passé dans les échecs.
Quand Deep Blue a battu Kasparov en 1997, tout le monde a dit que c’était la fin des échecs. Personne ne voudrait plus jouer contre des humains. Plus personne ne s’entraînerait. Les échecs allaient mourir.
28 ans plus tard, il y a plus de joueurs d’échecs que jamais. Les IA ont poussé les meilleurs à être encore meilleurs. Les compétitions humaines existent toujours, avec des règles adaptées. Et les IA sont devenues des outils d’entraînement incontournables.
Ce n’est pas parce qu’on a des IA capables de battre n’importe qui aux échecs qu’on arrête les échecs.
Le CTF va peut-être suivre le même chemin. C’est douloureux maintenant – comme chaque transition. Mais la communauté cyber a toujours su rebondir. Les challenges peuvent évoluer. Les règles peuvent s’adapter. Et je suis sincèrement désolé que cette transition arrive avant que certains n’aient eu la chance de participer à un CTF « à l’ancienne » sans se poser ces questions. Mais les temps changent, qu’on le veuille ou non.
Pour l’instant, c’est décourageant. Mais il y a un moment où ça va pousser les meilleurs à être encore meilleurs. Et moi, ce que je veux voir, c’est des gens qui viennent avec des IA exotiques entraînées dans leur garage et qui trouvent des 0-days. Pas des gens qui se brident pour respecter des règles impossibles à vérifier.
Bien ou Mal ?
Vous avez sans doute ressenti, à la lecture de cet article, que je faisais la promotion de ce systéme. Pourtant, ce n’est pas le cas. Cette session de 2h24 m’aurait coûté environ 1 000 $ si j’avais utilisé l’API. Cela amène naturellement à une réflexion : celui qui paie le plus gagne-t-il ?
Mais cet avantage financier n’est pas nouveau. Dans de nombreux domaines compétitifs, l’avantage revient déjà à ceux qui ont accès aux meilleurs outils, aux offres professionnelles, aux services premium ou à davantage de ressources. L’argent influence depuis longtemps les performances et les résultats.
Est-ce que l’IA change l’échelle du problème ? Probablement. Est-ce qu’il faut la considérer comme une nouvelle génération d’outils, au même titre que d’autres avancées technologiques qui ont transformé leur domaine ? Peut-être.
Attention, je ne dis pas que c’est une bonne chose. Je ne dis pas non plus que tout le monde doit adopter cette approche, ni qu’il faut remplacer les CTF actuels. Au contraire, je suis le premier à avoir appris et construit mes bases grâce aux CTFs, et je ne peux qu’encourager chacun à en faire le plus possible « à la main ». C’est là que se construisent les réflexes, la compréhension et l’expertise.
Mais la question reste entière : comment relever le défi face à des attaquants qui utilisent déjà des systèmes automatisés ? Et surtout, comment apprendre à maîtriser ces mêmes systèmes dans un cadre légal, éthique et pédagogique ?
Peut-être que le véritable enjeu n’est pas de savoir si ces outils doivent exister ou être utilisés, mais plutôt de comprendre comment former les futurs attaquants et défenseurs à travailler dans un monde où ils sont déjà une réalité.
Est-ce que j’ai vraiment joué ?
C’est probablement la question qui m’a le plus travaillé après coup. Parce qu’au fond, si on retire le score, les first bloods et le stunt, qu’est-ce que j’ai réellement accompli ce soir-là ? J’ai construit un système capable de résoudre des challenges. Mais est-ce que moi, j’ai résolu les challenges ?
La réponse honnête, c’est : pas vraiment. Ou du moins, pas de la manière dont je les aurais résolus dans un CTF classique.
Quand je fais un challenge à la main, je passe du temps à me tromper. Je lis du code. Je cherche une piste. Je m’enferme parfois dans une mauvaise direction pendant vingt minutes avant d’avoir un déclic. Je découvre un concept que je ne connaissais pas. Je retiens une technique parce que j’ai souffert pour la comprendre. Cette fois-ci, ce n’était pas ça.
J’ai appris à construire une machine capable de chercher à ma place. J’ai appris à coordonner plusieurs agents. J’ai appris à structurer un workflow, à construire un RAG pertinent, à développer un skill spécialisé, à orienter les modèles, à reconnaître leurs erreurs et à les corriger.
J’ai appris énormément de choses. Mais je n’ai presque rien appris sur les challenges eux-mêmes.
Si demain vous me redonnez certains de ces challenges sans mes outils, il est probable que je sois incapable de les refaire aussi vite. Peut-être même incapable de les refaire tout court pour certains d’entre eux.
C’est là toute l’ambiguïté.
D’un côté, j’ai acquis une compétence qui sera probablement utile dans le monde réel : savoir construire et piloter des systèmes automatisés capables d’analyser des problèmes complexes. De l’autre, je n’ai pas renforcé mes fondamentaux de la même manière qu’un joueur qui aurait passé sa soirée à résoudre chaque challenge lui-même.
Et c’est peut-être là que se trouve la vraie limite de l’exercice.
Les CTF n’ont jamais servi uniquement à trouver des flags. Ils servent à apprendre, à développer son intuition, à accumuler des réflexes et à construire une culture technique. En déléguant une partie de ce travail à l’IA, on gagne en performance immédiate mais on risque aussi de perdre une partie de cet apprentissage.
Alors est-ce que j’ai joué ?
Oui, dans le sens où j’ai conçu, piloté et exploité un système complexe pour atteindre un objectif.
Mais non, dans le sens où je n’ai pas vécu l’expérience traditionnelle du CTF telle que je l’ai connue pendant dix ans.
Et c’est précisément pour cette raison que je pense que les CTF « à l’ancienne » ont encore une valeur immense. Parce qu’avant de déléguer à une machine, il faut d’abord apprendre à faire soi-même. Sinon, on finit par savoir construire une machine qui résout les problèmes sans être capable de les résoudre soi-même.
En résumé
Les règles étaient claires. Je les ai enfreintes en connaissance de cause, dans le cadre d’un stunt assumé. J’ai été le premier à me signaler. J’ai été passé en hidden – hors compétition mais pas banni, je peux continuer les challenges. C’est cohérent avec les règles et je n’ai rien contesté.
Ce que je ne voulais surtout pas, c’est que ça soit perçu comme de la triche. Un tricheur se cache. Moi j’ai fait #1 en 2h30 de manière tellement flagrante que le scoreboard criait le stunt tout seul, et je suis allé toquer à la porte des orgas avant qu’ils n’aient besoin de venir me chercher. C’est la différence entre quelqu’un qui triche pour gagner et quelqu’un qui pousse un système à ses limites pour montrer qu’il faut en parler.
La question que je pose reste ouverte : où est la limite entre un outil et de la triche quand tout embarque de l’IA ? Et comment on fait évoluer les CTF pour que cette question ait une réponse claire ?
En attendant : 21 challenges, 2h30, #1 pendant 2 heures, une recette de tarte aux fraises envoyée aux orgas après un test de prompt injection sur ma personne, et un bon débat lancé.
GG à tous les participants. Merci aux orgas pour leur fairplay et leur réactivité.
Les chiffres
| Métrique | Valeur |
|---|---|
| Durée de la session | ~2h30 |
| Challenges résolus | 21/64 |
| Score max | ~7050 pts |
| Rang max | #1 (avant hidden) |
| Avance sur le #2 | +3562 pts |
| First bloods | 6 (Wall Of Patents, Télégraphe Détourné, Tour de RSA, Too big or too small, J’optimise le porte à portes, Le nouveau de Broglie) |
| Échecs | 3 |
| Instances crashées | 2 |
| Vitesse moyenne | 1 challenge / 7 min |
| Stack | Claude Opus + Codex + Llama 3.2 RAG + outils classiques |
| Tartes aux fraises | 1 |
21 challenges. 7036 pts. #1. 6 first bloods. gg.
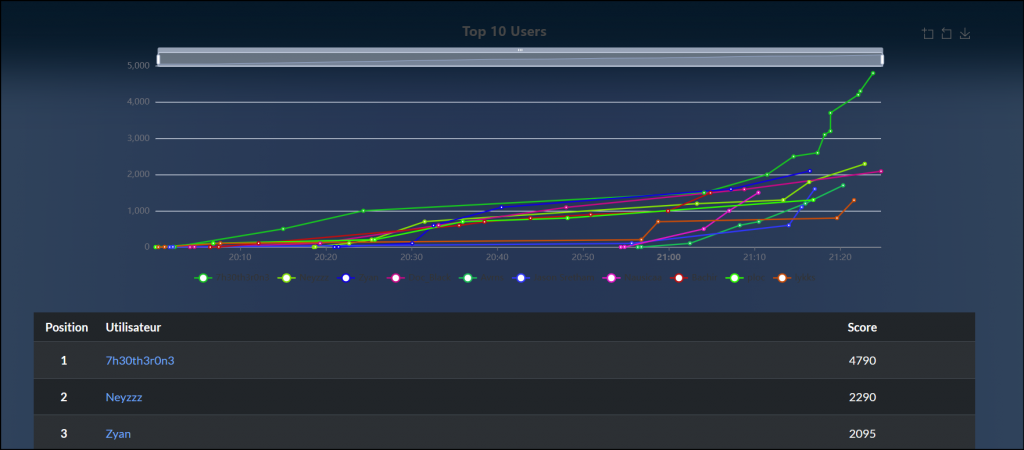
pas la photo final, mais on comprend mieux pourquoi on m’a passé en hidden.
Remerciement
Je tiens à remercier chaleureusement toute l’équipe organisatrice du 404CTF pour leur travail colossal et la qualité exceptionnelle de cette édition.<
Au-delà des challenges, de l’infrastructure et de l’organisation générale, je veux souligner leur professionnalisme et leur fair-play dans la gestion de ma situation particulière. Les échanges ont toujours été respectueux, transparents et constructifs, malgré un contexte qui aurait pu être bien plus tendu.
Merci également pour les discussions passionnantes que cet épisode a permises en coulisses. Même lorsque nous n’étions pas forcément d’accord sur tout, les échanges ont toujours été intelligents, bienveillants et orientés vers l’avenir de la discipline.
Enfin, merci pour les dizaines d’heures de travail nécessaires à la création de cet événement. Organiser un CTF de cette ampleur représente un investissement énorme, souvent peu visible de l’extérieur. Sans les bénévoles, auteurs de challenges, infrastructure, support et coordination, rien de tout cela n’existerait.
GG à toute l’équipe du 404CTF, à la DGSE, à Télécom SudParis et à tous ceux qui ont contribué à faire de cette édition un événement mémorable.
Laisser un commentaire